(no subject)
Dec. 13th, 2022 09:15 pmhow to stop AI image generators from using your art on your portfolio / personal site in 4 steps
Stopping artist's works from being scraped off of social media like twitter or tumblr is an impossible ask (unless the accounts are deleted), however - I had been wondering for a while if there was a way to stop dataset crawlers from scraping images off of portfolio and/or personal sites.![[personal profile]](https://www.dreamwidth.org/img/silk/identity/user.png) armaina was kind to mention elsewhere that LAION (a large dataset for many of the common AI image generators as of this writing) used Common Crawler as the "engine" to scrape images to be fed to the dataset.
armaina was kind to mention elsewhere that LAION (a large dataset for many of the common AI image generators as of this writing) used Common Crawler as the "engine" to scrape images to be fed to the dataset.
The good news is that CommonCrawler respects the robots.txt file which you can set up on your site in less than 10 minutes.
robots.txt is a file you can add to your site (with a very long history of being used) that traditionally can keep search engines and bots (like google) from scraping info and images from your site. We won't be talking about blocking other search engines / bots here, rather focusing on CommonCrawler to ideally create friction between AI image generators and art hosted on your portfolio / personal sites (though this method will likely work with other crawlers should more be created, as long as this file is updated).
How to do it:
1) open up a .txt document in a program like textedit or notepad, and label it robots.txt
(note this cannot be a .doc or other file type)

2) put absolutely nothing in the file except for the four lines below (remove the bullet points if they're copied over). CommonCrawl provides their user-agent string (the top one) on this page; I've added the second user-agent to make it easier to validate the document, though you're welcome to change it to a different one.
4) validate the robots.txt document is working! there's several validators out there, the one I just used is - https://technicalseo.com/tools/robots-txt/ as it's fairly straightforward. plug in your url (make sure to have the https:// part), select the AdSense option in the drop-down (you may recognize the user agent), and hit "test". It'll tell you if it's working or not!
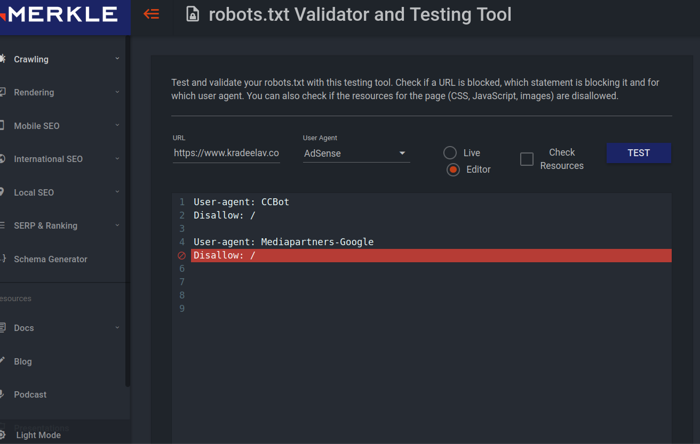
And done ~ if it validated correctly, your site should now be telling CommonCrawler that it should not scrape images from your site/domain.
I am learning this as I go along, so if you run into errors, I may not be able to help. If you give it a good honest google though, would be happy to brainstorm problems in the comments, as long as energy bandwidth permits. :)
EDIT, METHOD 2:

Stopping artist's works from being scraped off of social media like twitter or tumblr is an impossible ask (unless the accounts are deleted), however - I had been wondering for a while if there was a way to stop dataset crawlers from scraping images off of portfolio and/or personal sites.
The good news is that CommonCrawler respects the robots.txt file which you can set up on your site in less than 10 minutes.
robots.txt is a file you can add to your site (with a very long history of being used) that traditionally can keep search engines and bots (like google) from scraping info and images from your site. We won't be talking about blocking other search engines / bots here, rather focusing on CommonCrawler to ideally create friction between AI image generators and art hosted on your portfolio / personal sites (though this method will likely work with other crawlers should more be created, as long as this file is updated).
How to do it:
1) open up a .txt document in a program like textedit or notepad, and label it robots.txt
(note this cannot be a .doc or other file type)
2) put absolutely nothing in the file except for the four lines below (remove the bullet points if they're copied over). CommonCrawl provides their user-agent string (the top one) on this page; I've added the second user-agent to make it easier to validate the document, though you're welcome to change it to a different one.
User-agent: CCBotDisallow: /User-agent: Mediapartners-GoogleDisallow: /
4) validate the robots.txt document is working! there's several validators out there, the one I just used is - https://technicalseo.com/tools/robots-txt/ as it's fairly straightforward. plug in your url (make sure to have the https:// part), select the AdSense option in the drop-down (you may recognize the user agent), and hit "test". It'll tell you if it's working or not!
And done ~ if it validated correctly, your site should now be telling CommonCrawler that it should not scrape images from your site/domain.
I am learning this as I go along, so if you run into errors, I may not be able to help. If you give it a good honest google though, would be happy to brainstorm problems in the comments, as long as energy bandwidth permits. :)
EDIT, METHOD 2:
another easier option to remove your personal/portfolio art site from AI image datasets: apparently you can email CommonCrawl with the below information, and they'll remove it.
(text from an email I got from info (at) commoncrawl (dot) org)
(no subject)
Date: 2022-12-14 07:05 pm (UTC)(no subject)
Date: 2022-12-14 07:25 pm (UTC)(no subject)
Date: 2022-12-16 10:54 am (UTC)Just wanted to add that you can also add deviantart's new NOAI metatag to the head of your html, too! The details on how you do this are towards the end of this post on deviantart: https://www.deviantart.com/team/journal/UPDATE-All-Deviations-Are-Opted-Out-of-AI-Datasets-934500371
Currently LAION will respect this metatag, so you'd be doubly protecting your page with it by also setting up the robots.txt, but also it's a little more future proof against any new AI image generators that get made that decide to use their own dataset that happen to use some other crawler. Still no guarantee but also robots.txt is also not guaranteed, so anything you can do to further opt out the better!
(no subject)
Date: 2022-12-16 05:41 pm (UTC)